In Apache Cassandra, your data is distributed across several nodes. The partitioner is responsible to calculate the correct partition with regards to your row key so Cassandra knows where to place the copies of your data. You can choose among several strategies. New users might be tempted to use the ByteOrderedPartitioner as this allows for a ranged row query. But everybody on the Internet says that this is pretty bad. Find out why.
A Typical Use Case
I like to do experiments to get some empirical reasoning on why to use this or that. This is one of the experiments we do in our Cassandra Trainings, and it usually is pretty convincing to people wanting to use the ByteOrdererPartitioner.
I’ll start off with one typical use case you might encounter when using Cassandra.
Suppose you have a column family that stores user data. I’ll keep it simple for this experiment: The colum family stores the user name (as row key) along with some other information like full name, e-mail address, birth date. You might encounter this data structure in some applications using Cassandra.
Our test data might look something like this:
User data structure with two entries
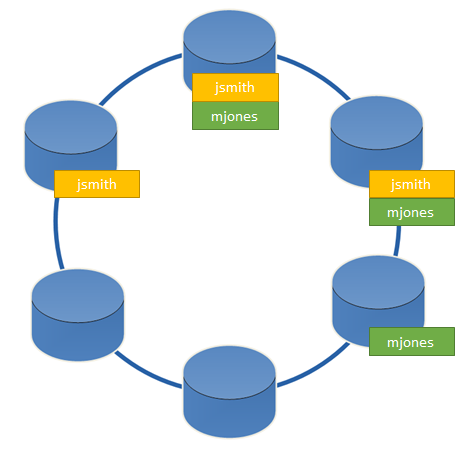
Cassandra uses the row key (in our case, that is the user name) to decide on which node(s) the replicas of the data will be stored. This is whay the row key is sometimes also referred to as partition key: It is used to define the partition this key belongs to. So your data might be distributed similar to this:

Data partitioned in Apache Cassandra
In our example, the two user entries would be stored on different nodes. We would use a replication factor of three, which means that three copies of each piece of data are stored in the cluster.
The Theory: Partitioning in Cassandra
Partitioning is used to determine where the data will be stored. For data I want to write or read, Cassandra calculates the token of the row key. Each node in the Cassandra cluster has a range of tokens (it’s actually called the token range) it is responsible for. Cassandra uses a token and not the plain row key because row keys in different column families can be of different types, for example Strings or UUIDs. So the row keys have to be mapped to one common token somehow.
The calculation of the partition (and the token itself) is performed by partitioners that are configured on a per-cluster basis. There are several types of partitioners you can choose from belonging to the following two categories:
- Ordererd partitioning: The ByteOrderedPartitioner and the OrderPreserving partitioner belong in this category. They essentially look at the first byte(s) of the row key and use this to decide where the data will land. The data will be placed in order in the Cassandra ring. The token for ‘C’ will always be placed after the token for ‘A’.
- Random partitioning: The RandomPartitioner and the Murmur3Partitioner (introduced in Cassandra 1.2) are members of this category. They take a different approach: Instead of using the plain bytes of the row key, they calculate a hash value (MD5 or Murmur3) of the row key and use this for partitioning the data. This effectively means that the data is distributed more or less randomly over the Cassandra cluster, as hash(‘A’) might not necessarily be smaller than hash(‘C’) – in the case of MD5, it is not.
This has one very important implication: When using the ByteOrderedPartitioner, you can query over rows in ordered fashion. You are able to return all users ordered by their user name. You can query for all users starting with the letter “A”. When using random partitioning, you cannot, as you will get the data in the order of the hash key, not in the order of the underlying value.
So, you should use the ByteOrderedPartitioner, right? It gives you the possibilites to do an ordered scan over the user database.
Unfortunately, ordered partitioning has severe downsides: The data will not be distributed evenly among the Cassandra nodes. This causes your data to be unevenly distributed. But it it that bad? Let’s find out in our experiment.
Designing The Experiment
First names of newborns in Austria
Consider our use case with the user name as the row key. Very often, users will use their real name to create their username, like our two test users jsmith and mjones. The ByteOrderedPartitioner uses the first byte(s) of the row key to calculate the token, so the first letter of the username will have a major impact on the calculated partition.
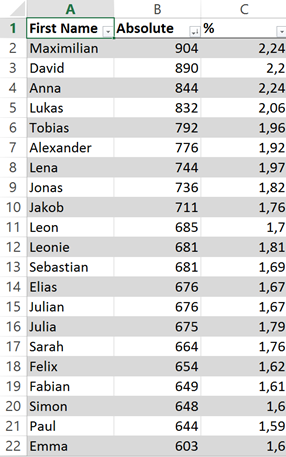
We can use that for our experiment: I’m Austrian, so let’s assume that a random set of the population of Austria is using our application. Statistik Austria publishes the first names of all new-borns in Austria. For this experiment, we’re using the data of 2011, which includes all the names of new-borns with 5 or more mentions. Using this statistic requires some preprocessing because it is only available in PDF format, but if you want to do the work. you can easily reproduce the table with the most common Austrian names. We will use this as our test data to look at the distribution of the data.
In the excerpt of the table on the right, you can see the most common names. Of course, this data is not evenly distributed with regards to the first letter. You can see that there are mnay names starting with L and J.
Results Using ByteOrderedPartitioner
To measure the distribution of the names, we are going to look at the first letter of the first name and then assign one of four evenly-sized buckets for this name. This means that if the first letter of a name is “D”, it would go into bucket 1 which has a range from A to G. The test data set consists of more than 1300 distinct names with a total of more than 65000 occurences. If you assign the bucket for each name and sum up the amount of occurences in each bucket, you will receive a distribution similar to this:
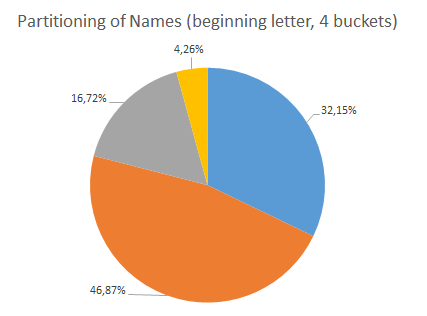
Name Distribution with Ordered Partitioning
You can see that the distribution of the data is very ill-balanced. There is one bucket with nearly 50%, whereas the smallest bucket has less than 5%. Translating this to a Cassandra cluster, this would mean that the majoritiy of the load would go to one or more particular nodes, whereas some nodes are hardly storing any data.
Results Using RandomOrderPartitioner

MD5 of Leon and Leonie
We can use the same set of data to simulate the behavior of the RandomOrderPartitioner as well. In order to do this, we need to calculate the MD5 hash of all the names. One of the properties of good hash algorithms is that they distribute the data balanced accross the whole key space.
Take a look at the picture at the right for example: “Leon” (male) and “Leonie” (female) are ranked #11 and #12 in the test data set. When using the ByteOrderedPartitionier, you can be fairly sure that they will be put into the same bucket. However, the MD5 hash of both entries is very different, so these names will be placed in distinct buckets.
Again, we define 4 buckets. Here is the result for the RandomOrderPartitioner:
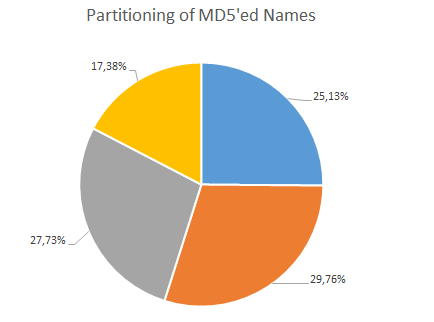
Name Distribution with Random Partitioning
While the distribution is not perfect, it is much better than with the ordered partitioner. And it was done automagically, thanks to mathematics.
But I can manually balance the cluster, right!?
Yes, you can. Theoretically. But it will require constant manual intervention, and only work to some extend.
In this experiment, I created even-sized buckets according to the first letter of the name. If I had the same thing on a live cluster, I would need to move data around, which results in high loads on the nodes for the movement of the data.
Consider that the data we store is not just a user data base, but also some time series data where the row key is a timestamp or TimeUUID. When using the RandomPartitioner, this is no problem: The hash algorithm will also distribute the timestamps evenly, avoiding the need to rebalance the whole Cassandra ring. It can live happily on the same cluster as our user database.
With the ByteOrderedPartitioner, consquent timestamps will go onto the same node. So all the load is placed on just one node and its replicas. This is pretty bad and a problem that is not easy to solve. Besides: If both column families are living in the same cluster, you might end up with one of the two column families being bound to very few nodes.
Summary
The experiment shows that the ByteOrderedPartitioner will result in a Cassandra cluster that is not well balanced. This can cause bottlenecks in your application as most of the data will be stored on very few machines. If you are using different types of row keys for different column families, good rebalancing will become next-to-impossible.
So to sum this up: The Internet is right, don’t use the ByteOrderedPartitioner. Think about if you really need ranged row queries (the only good side about ordered partitioning). Usually, there are other ways to implement the desired behavior, depending on your intended queries.
Latest posts by Gernot R. Bauer (see all)
- This was Cassandra Meetup in Vienna - 2014-01-20
- Announcement: First Cassandra Meetup Vienna on January 13, 2014 - 2014-01-09
- Cassandra Summit Europe 2013 - 2013-10-26